How to Approach Regression Analysis Assignments Effectively

Claim Your Discount Today
Get 10% off on all Statistics Homework at statisticshomeworkhelp.com! This Spring Semester, use code SHHR10OFF to save on assignments like Probability, Regression Analysis, and Hypothesis Testing. Our experts provide accurate solutions with timely delivery to help you excel. Don’t miss out—this limited-time offer won’t last forever. Claim your discount today!
We Accept









- Understanding Regression Analysis
- Identifying Variables
- Developing a Theoretical Framework
- Data Considerations
- Model Specification and Execution
- Interpretation of Results
- Addressing Causal Inference Challenges
- Conclusion
Regression analysis is a fundamental statistical tool used to understand relationships between variables. Assignments requiring regression analysis often involve identifying dependent and independent variables, selecting control variables, and performing Ordinary Least Squares (OLS) regression. This blog provides a structured approach to solving such assignments, ensuring clarity and methodological soundness. While this guide aligns closely with the provided assignment structure, it remains broadly applicable to any similar regression analysis assignment. Statistics homework help services can be invaluable when tackling complex regression tasks, as they provide expert insights and structured guidance. Many students struggle with regression analysis due to its reliance on statistical theories, data interpretation, and model validation, making professional assistance crucial. One of the key challenges in completing these assignments is ensuring accurate variable selection, proper hypothesis formulation, and appropriate control variable inclusion. Those who seek help with regression analysis homework can benefit from structured methodologies that streamline data handling, regression execution, and interpretation of results. By following a systematic approach, students can confidently navigate regression assignments, improving their analytical skills and statistical knowledge. Understanding the significance of theoretical justification, model accuracy, and causal inference ensures that regression results are meaningful and reliable. With the right strategies and guidance, students can efficiently complete their assignments and develop a strong foundation in statistical analysis.
Understanding Regression Analysis

Regression analysis estimates the relationship between a dependent variable and one or more independent variables. The most commonly used method is OLS regression, which minimizes the sum of squared residuals to estimate coefficients. The primary objectives of regression analysis assignments include:
- Identifying relationships between variables
- Making predictions based on data
- Understanding causality and confounding factors
- Evaluating model performance
Identifying Variables
Selecting appropriate variables is crucial for a meaningful regression analysis. The dependent variable represents the outcome being studied, while independent variables serve as predictors. Additionally, control variables help account for potential confounders, ensuring more accurate estimates. Thoughtful variable selection enhances the validity and interpretability of regression models. A regression analysis requires careful selection of variables. Assignments typically specify a dataset from which students must choose:
- Dependent Variable: The outcome being predicted or explained.
- Independent Variable: The primary predictor influencing the dependent variable.
- Control Variables: Additional variables included to reduce bias and isolate the effect of the independent variable.
A well-chosen dependent variable is either continuous or dichotomous, ensuring suitability for OLS regression. The independent variable should have a plausible theoretical connection to the dependent variable, and control variables should be selected based on potential confounding influences.
Developing a Theoretical Framework
A strong theoretical foundation guides regression analysis by establishing logical relationships between variables. The framework should define the expected direction of relationships, explain causal mechanisms, and consider alternative explanations. A well-developed theory ensures that the regression model is conceptually sound and empirically justified. Theoretical justification is crucial in regression assignments. Before running a regression, students must establish a hypothesis about the expected relationship between variables. This involves:
- Defining the Expected Relationship: Is the independent variable positively or negatively associated with the dependent variable?
- Establishing Causality: Does the independent variable influence the dependent variable through a credible mechanism?
- Considering Alternative Explanations: What other factors might affect the relationship?
For instance, if studying the effect of education level on income, the hypothesis might state that higher education leads to higher earnings due to increased skills and job opportunities.
Data Considerations
Data quality and structure significantly impact regression analysis outcomes. Researchers must consider whether the data is observational or experimental, cross-sectional or time-series. Proper data cleaning, handling of missing values, and transformation of categorical variables are essential steps in preparing a dataset for analysis. The dataset’s structure influences the regression approach. Key considerations include:
- Observational vs. Experimental Data: Observational data requires careful control of confounding variables.
- Cross-Sectional vs. Time-Series Analysis: Cross-sectional analysis examines a single time point, while time-series analysis tracks changes over time.
- Data Cleaning and Preparation: Checking for missing values, ensuring variable consistency, and transforming categorical variables if necessary.
Model Specification and Execution
Regression models should be carefully specified to avoid biases and inaccuracies. Assignments often require running multiple OLS regressions, progressively adding control variables to observe changes in coefficient estimates. The standard regression equation accounts for dependent and independent variables, control variables, and error terms to ensure robust estimations. After defining variables and the theoretical framework, the next step is model specification. A typical assignment involves estimating three models:
- A simple regression with only the dependent and independent variable.
- A regression including one control variable.
- A regression including two control variables.
The standard OLS regression equation is:
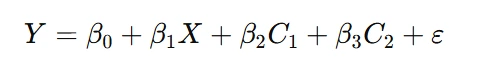
where:
- Y is the dependent variable.
- X is the independent variable.
- C1 and C2 are control variables.
- ε is the error term.
Interpretation of Results
Interpreting regression results involves analyzing coefficient estimates, statistical significance, and model fit. Key elements include determining the sign and magnitude of coefficients, assessing p-values for significance, and evaluating the R-squared value. Changes in coefficients when control variables are added can indicate potential confounding effects, helping to refine conclusions. Interpreting regression results requires examining coefficient estimates, significance levels, and overall model fit:
- Coefficient Sign and Magnitude: A positive coefficient indicates a direct relationship, while a negative coefficient suggests an inverse relationship.
- Statistical Significance (p-values): Indicates whether the independent variable has a meaningful effect on the dependent variable.
- R-squared (R2R^2) Value: Measures the proportion of variance explained by the model.
- Effect of Control Variables: Understanding whether adding controls alters the relationship between the independent and dependent variable.
Addressing Causal Inference Challenges
Causal inference is one of the most critical aspects of regression analysis. Researchers must account for omitted variable bias, endogeneity, and multicollinearity, as these issues can distort results. Employing robustness checks, instrumental variables, and sensitivity analyses can improve the reliability of causal interpretations, ensuring valid conclusions from regression models. Causal inference is a common challenge in regression assignments. Students must consider:
- Omitted Variable Bias: Unmeasured factors influencing both the independent and dependent variable can distort results.
- Endogeneity: Reverse causality or simultaneity can bias coefficient estimates.
- Multicollinearity: High correlation between independent variables can inflate standard errors.
Solutions include carefully selecting control variables, using instrumental variables (if applicable), and ensuring robustness through sensitivity analyses.
Conclusion
Successfully completing a regression analysis assignment requires a structured approach encompassing theoretical justification, careful data selection, proper model specification, and thorough result interpretation. By following this framework, students can conduct rigorous and insightful regression analyses, drawing meaningful conclusions from their data. This methodical approach ensures assignments are not only well-structured but also demonstrate a deep understanding of statistical principles.