Solving Data Clustering Assignments in Statistics

Claim Your Discount Today
Get 10% off on all Statistics homework at statisticshomeworkhelp.com! Whether it’s Probability, Regression Analysis, or Hypothesis Testing, our experts are ready to help you excel. Don’t miss out—grab this offer today! Our dedicated team ensures accurate solutions and timely delivery, boosting your grades and confidence. Hurry, this limited-time discount won’t last forever!
We Accept









- Understanding the Problem Statement
- Step 1: Choosing the Clustering Approach
- Step 2: Computing Distance Metrics
- Step 3: Hierarchical Clustering Methods
- Step 4: Standardization and Its Impact
- Step 5: K-Means Clustering
- Step 6: Comparing Results and Selecting the Best Model
- Step 7: Visualizing Clusters
- Conclusion
Clustering is a fundamental unsupervised learning technique in statistics and data science. It involves grouping similar data points based on specific distance metrics and linkage methods. Assignments related to clustering typically require students to analyze datasets using various clustering methods such as hierarchical clustering and K-means. Seeking statistics homework help can be beneficial when tackling these complex assignments, as understanding the nuances of distance metrics, standardization, and clustering evaluation can be challenging. The process includes choosing the right clustering method, computing distances, standardizing data when necessary, and analyzing the results using visualization techniques. Furthermore, students often need to compare hierarchical and partition-based clustering approaches to determine the optimal number of clusters. A strong grasp of these concepts is essential to ensure accuracy and effectiveness in statistical analysis. Additionally, clustering assignments frequently overlap with other statistical techniques, making it useful to seek guidance, especially for those needing help with data mining homework. By leveraging theoretical frameworks and structured methodologies, students can confidently approach clustering assignments and derive meaningful insights from their datasets. This blog provides a structured theoretical approach to solving such assignments, closely reflecting the requirements seen in practical academic exercises.
Understanding the Problem Statement

Clustering assignments require a clear understanding of the dataset, including variable selection and interpretation. Defining similarity measures such as Euclidean distance helps determine how data points relate to one another. A well-structured problem statement outlines the required analysis, expected outcomes, and justification for methodology selection, ensuring a systematic approach to solving clustering tasks. Before diving into the solution, it is essential to:
- Understand the dataset – Identify the variables and their significance.
- Define the distance metric – Euclidean distance is commonly used, but alternatives exist.
- Choose a clustering method – Hierarchical clustering (single linkage, Ward’s method) and K-means are frequently used.
- Standardization of data – Determine whether standardizing the dataset affects clustering outcomes.
- Visualization and validation – Use dendrograms, PCA, or multidimensional scaling to validate cluster assignments.
Step 1: Choosing the Clustering Approach
Selecting the appropriate clustering technique is crucial. Hierarchical clustering, which builds a nested structure of clusters, and K-means, which partitions data into K groups, are widely used. The choice depends on the dataset characteristics, interpretability, and desired outcome. Hierarchical clustering provides a visual representation through dendrograms, while K-means is computationally efficient for larger datasets. Two primary clustering approaches are commonly used:
- Hierarchical clustering – Builds a tree-like structure (dendrogram) to show nested groupings of data.
- Partition-based clustering (e.g., K-means) – Divides data into K predefined clusters based on similarity.
Each approach has distinct advantages, and assignments often require comparing them.
Step 2: Computing Distance Metrics
The fundamental step in clustering is measuring similarity between data points. The Euclidean distance formula is:
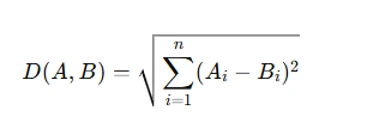
where Ai and Bi are the feature values of two observations. This metric is widely used in clustering due to its intuitive geometric interpretation.
Step 3: Hierarchical Clustering Methods
Hierarchical clustering organizes data into nested clusters using linkage criteria such as single linkage (shortest distance) and Ward’s method (minimizing variance within clusters). A dendrogram visually represents these clusters, aiding in determining the optimal number of groups. This method is advantageous for small to medium-sized datasets where hierarchical relationships are meaningful. Hierarchical clustering constructs a dendrogram based on a linkage criterion. Common methods include:
- Single linkage – Merges clusters based on the shortest pairwise distance.
- Ward’s method – Minimizes variance within clusters, resulting in compact groups
To implement hierarchical clustering:
- Compute the distance matrix.
- Apply the chosen linkage method.
- Construct and analyze the dendrogram to determine the optimal number of clusters.
Step 4: Standardization and Its Impact
Data standardization is crucial when dealing with variables measured on different scales. It transforms the data as follows:
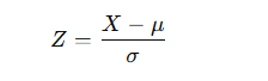
where μ is the mean and σ is the standard deviation.
Standardization affects clustering because:
- It prevents variables with large numerical ranges from dominating distance computations.
- It ensures fair comparison among all features.
Step 5: K-Means Clustering
K-means clustering partitions data into a predefined number of clusters by iteratively assigning points to centroids and updating these centroids based on cluster members. The Elbow Method and Silhouette Score assist in selecting the optimal number of clusters. K-means is efficient but sensitive to initial centroid selection and requires predefined K values. K-means clustering is another common approach that minimizes intra-cluster variance. The algorithm follows these steps:
- Select an initial number of clusters KK.
- Assign each data point to the nearest cluster centroid.
- Compute new centroids based on cluster members.
- Iterate until convergence.
The choice of KK can be guided by:
- The Elbow Method – Analyzing the within-cluster sum of squares (WCSS).
- The Silhouette Score – Measuring cohesion and separation among clusters.
Step 6: Comparing Results and Selecting the Best Model
Evaluating clustering performance involves comparing different methods and analyzing their stability. Internal validation metrics such as inertia (for K-means) and dendrogram structure (for hierarchical clustering) help determine the most suitable approach. Cross-validation and domain knowledge further refine model selection. After clustering using hierarchical and K-means approaches, it is essential to:
- Compare the clusters obtained from different methods.
- Evaluate stability using cross-validation techniques.
- Interpret cluster characteristics based on domain knowledge.
Step 7: Visualizing Clusters
Visualization techniques such as Principal Component Analysis (PCA) and Multidimensional Scaling (MDS) facilitate cluster interpretation. PCA reduces data dimensions while preserving variance, and MDS maintains pairwise distances, allowing for better insight into cluster separability and effectiveness. Cluster visualization enhances interpretability. Principal Component Analysis (PCA) and Multidimensional Scaling (MDS) are commonly used techniques.
- PCA reduces high-dimensional data to two or three dimensions while retaining maximum variance.
- MDS preserves pairwise distances to represent data in a lower-dimensional space.
By plotting the clusters, one can assess whether the separation is meaningful and aligns with prior expectations.
Conclusion
Successfully solving clustering assignments requires a structured approach: understanding the dataset, selecting appropriate clustering methods, standardizing data when necessary, comparing results, and visualizing the final clusters. Following these theoretical steps ensures clarity and accuracy while tackling any clustering-based statistical assignment.