How to Approach and Solve Multiple Regression Analysis Assignments
.webp)
Claim Your Discount Today
Get 10% off on all Statistics homework at statisticshomeworkhelp.com! Whether it’s Probability, Regression Analysis, or Hypothesis Testing, our experts are ready to help you excel. Don’t miss out—grab this offer today! Our dedicated team ensures accurate solutions and timely delivery, boosting your grades and confidence. Hurry, this limited-time discount won’t last forever!
We Accept









- Defining the Assignment Scope
- Key Components to Address
- Example Framework
- Methods: Designing the Study
- Research Design
- Procedures
- Data Preparation and Analysis
- Data Preparation
- Inferential Analysis
- Discussion
- Interpreting Results
- Practical Applications
- Conclusion
Multiple regression analysis is a cornerstone in statistical research, offering a robust method to predict the value of one dependent variable based on multiple independent variables. This statistical technique is widely used across various fields, including social sciences, business analytics, and psychology, due to its ability to analyze complex relationships between variables. When faced with an assignment involving multiple regression analysis, adopting a structured approach is essential to ensure both theoretical rigor and practical execution.
Understanding the nuances of multiple regression analysis is critical, particularly if you are seeking statistics homework help to tackle challenging academic tasks. This method allows researchers to uncover significant relationships between predictors and outcomes, providing valuable insights that drive decision-making and strategy formulation. By focusing on key aspects such as hypothesis formulation, variable definition, and accurate data analysis, students can confidently address even the most intricate assignments.
If you’re looking for help with regression analysis assignment tasks, this guide offers a comprehensive framework for success. It emphasizes the importance of preparing data, ensuring adherence to statistical assumptions, and interpreting results with clarity and precision. Whether you’re analyzing behavioral patterns, business trends, or psychological factors, mastering multiple regression equips you with the tools to derive meaningful conclusions. By following this systematic approach, students and professionals alike can produce high-quality, academically sound research that contributes to their respective fields, achieving academic and practical excellence in the process.

Defining the Assignment Scope
Defining the assignment scope is the initial step in addressing a multiple regression analysis task. It involves understanding the relationships between a dependent variable and multiple predictors while aligning the study’s objectives with academic and practical goals. For instance, if the research focuses on knowledge sharing, predictors such as contact quality, contact frequency, and friendship should be clearly conceptualized and operationalized. Developing research questions and hypotheses, such as "Does contact quality positively influence knowledge sharing?" provides a clear framework. This clarity in scope ensures a focused approach, making the assignment manageable and methodologically sound.
Key Components to Address
- Topic Justification: Why is the study relevant?
- Variable Definitions: How are the variables conceptualized and operationalized?
- Hypotheses Development: What relationships are expected, and why?
Example Framework
- Dependent Variable: Knowledge sharing, emotional support, etc.
- Independent Variables: Contact quality, contact frequency, friendship.
- Research Question: How do these predictors influence the dependent variable?
- Hypotheses:
- H1: Contact quality positively predicts knowledge sharing.
- H2: Contact frequency positively predicts knowledge sharing.
- H3: Friendship positively predicts knowledge sharing.
Clearly defining these components establishes the foundation for your research and guides subsequent steps.
Methods: Designing the Study
The design of a multiple regression study outlines how data will be collected, analyzed, and interpreted. A robust research design includes diverse participants recruited through methods like snowball sampling to ensure generalizability. Using validated scales for variables—like a Contact Quality Scale—and calculating reliability metrics such as Cronbach’s alpha ensures the integrity of measurements. Ethical considerations, including informed consent and anonymity, are paramount. Procedures like online surveys are efficient, and surveys should remain brief to maximize response rates. These steps create a solid foundation for reliable and replicable results.
Research Design
The research design specifies how data will be collected, analyzed, and interpreted. Aligning your design with the research question and hypotheses is crucial.
1. Participants:
- Ensure diverse demographics for generalizability.
- Use recruitment methods like snowball sampling, where participants recruit others, ensuring age group diversity.
2. Materials:
- Scales: Use validated measurement tools for variables. For example:
- Contact Quality Scale: Includes items such as "I feel respected by this person," rated on a Likert scale from 1 (Strongly Disagree) to 5 (Strongly Agree).
- Reliability Analysis: Calculate Cronbach’s alpha to ensure internal consistency (e.g., α > 0.70).
3. Ethical Considerations:
- Obtain ethical approval before data collection.
- Ensure participants provide informed consent and maintain their anonymity.
Procedures
- Recruitment: Leverage personal networks, professional contacts, or social media. Participants may recruit co-workers of a different age group (with at least a 10-year gap).
- Data Collection: Use online or in-person surveys, ensuring clarity and brevity to encourage participation.
- Duration: Keep survey completion times under 20 minutes.
Data Preparation and Analysis
Effective data preparation is crucial for meaningful analysis. Handling missing data through imputation or exclusion, calculating descriptive statistics (e.g., means, standard deviations), and ensuring adherence to regression assumptions like normality and multicollinearity are essential steps. Multiple regression models, specified with equations incorporating all predictors, reveal insights into relationships between variables. Results should be reported in APA style, including key statistics like R-squared values and coefficients, to convey findings clearly.
Data Preparation
After collecting data, it’s vital to prepare it for analysis by ensuring accuracy and completeness.
1. Handling Missing Data:
- Use imputation methods to estimate missing values or exclude cases with excessive missing data.
2. Descriptive Statistics:
- Compute means, standard deviations, and correlations for all variables.
- Example Output:
- Contact Quality: M = 4.2, SD = 0.5
- Contact Frequency: M = 3.8, SD = 0.7
- Friendship: M = 4.0, SD = 0.6
Inferential Analysis
Multiple regression analysis involves the following steps:
1. Regression Assumptions:
- Normality: Ensure the dependent variable follows a normal distribution.
- Linearity: Verify linear relationships between predictors and the dependent variable.
- Multicollinearity: Check variance inflation factor (VIF) values (≤ 10) to confirm predictors aren’t highly correlated.
2. Model Specification:
- Define the regression model, including all predictors.
- Example Equation
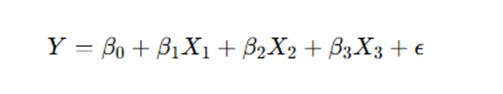
Where:
- Y: Dependent variable (e.g., Knowledge Sharing)
- β0: Intercept (the value of YYY when all predictors are zero)
- β1,β2,β3: Coefficients for the independent variables (e.g., Contact Quality, Contact Frequency, Friendship)
- X1,X2,X3 : Independent variables (predictors)
- ϵ: Error term (captures the variability in Y not explained by the predictors)
3. Reporting Results:
- Present results in APA style, including tables for coefficients, R-squared values, and F-statistics.
- Example: The model explained 45% of the variance in knowledge sharing,
Discussion
The discussion interprets results in light of hypotheses and theoretical frameworks. Significant findings are contextualized within existing literature, while limitations such as sample bias or self-report measures are acknowledged. Suggestions for future research, like longitudinal studies, offer pathways for further exploration. Practical applications, such as designing interventions to improve workplace dynamics, demonstrate the real-world relevance of findings. This comprehensive analysis not only addresses academic requirements but also contributes valuable insights to the field.
Interpreting Results
1. Hypotheses Testing:
- Summarize findings without excessive statistical jargon.
- Example: "Contact quality and friendship significantly predicted knowledge sharing, while contact frequency did not."
2. Theoretical Implications:
- Relate findings to existing literature.
- Example: "The significant effect of contact quality aligns with Smith et al.’s (2020) study on interpersonal dynamics."
3. Limitations:
- Discuss potential methodological flaws.
- Example: "The reliance on self-reported measures may have introduced social desirability bias."
4. Future Directions:
- Suggest improvements, such as longitudinal designs to assess causality.
Practical Applications
Organizations can leverage these findings to design interventions aimed at improving workplace relationships and enhancing knowledge sharing.
Conclusion
Successfully solving multiple regression analysis assignments requires a structured and methodical approach that integrates theoretical understanding and practical application. From defining the research scope and developing clear hypotheses to designing a robust study and preparing data for analysis, every step plays a vital role in ensuring accurate and meaningful results. Multiple regression analysis is a powerful tool for uncovering complex relationships between variables, offering insights that can drive both academic research and real-world decision-making. By adhering to statistical principles, such as ensuring normality, linearity, and the absence of multicollinearity, and employing proper reporting standards like APA style, students can effectively communicate their findings. Limitations, such as sample biases or the reliance on self-reported data, should be transparently addressed, and future directions for research should be thoughtfully considered to expand the study’s scope and relevance. Moreover, practical applications, such as designing organizational strategies to enhance knowledge sharing or improve interpersonal dynamics, highlight the value of regression analysis beyond the classroom. By approaching these assignments with rigor, clarity, and attention to detail, students not only fulfill academic requirements but also develop critical skills that contribute to their professional growth and understanding of statistical methodologies.